Introduction and problem description
At the beginning of a construction project, the architect's design is based on the wishes of the client as well as on existing laws and regulations. The technical construction and design drawings required for the execution are produced with the aid of CAD systems. The necessary construction work, the bill of quantities and the cost estimations are subsequently determined based on those.If there are changes in the design, the drawings and calculations concerning, for example, the structural design or the MEP (mechanical, electrical, plumbing) and HVAC (heating, ventilation, air conditioning) - have to be adjusted. In classical building design such adjustments cause a great deal of work and coordination overhead. The stated goal of Building Information Modeling (BIM) is to reduce the above mentioned workload.
The Industry Foundation Classes (IFC) are the implementation specification for the Building Information Modeling standard. They enable data exchange between different software applications of multiple stakeholders in the architecture, engineering and construction (AEC) industries working together throughout the life cycle of a building.
However, since the IFC-Standard is developed by many different domain experts with varying objectives, the standard has grown in complexity over the years, which places restrictions on its extensibility. For these reasons implementations of the standard are time-consuming and not always round-trip-capable in different existing software.
The aim of this project is to build a meta-model for a simplified and more object oriented approach of IFC, which enables extensibility and flexibility. Our model structure should allow an efficient integration of new knowledge and new products in the standard.
Methodology
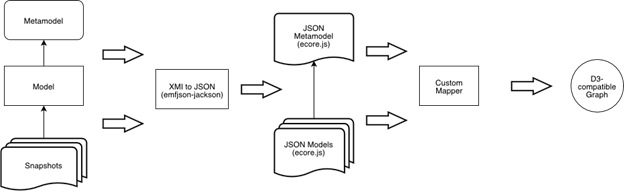
In this section we will discuss the steps necessary to create a representative meta-model of the IFC standard using the Eclipse Modeling Framework (EMF).For the first step (building the meta-model) we chose a small subset of types from the Shared Building Elements module for the definition of a closed space (e.g. a room). The chosen subset of the standard is a good representation of the concepts typical of IFC, because the IfcWall type is a complete product model as well as a fundamental part of a building and has most common functionality and properties of a building element.
- IFC Documentation - Research
To ensure that the existing technology is utilized to its fullest potential its purpose and usage have to be analyzed and compared to other existing standards.
- Development of a Class diagram
The complexity of IFC made the creation of a representative class diagram necessary before starting with the meta-model development. The class diagram provides a graphical representation of entities, abstract classes, their relationships and attributes. The main purpose of the class diagram was to aid in the selection of relevant entities and references for the type IfcWall and to determine which ones are insignificant enough to ignore.
- Object oriented approach
The next step is one of the most important steps in the object oriented approach. The fact that IFC is mainly developed by stakeholders such as building and mechanical engineers leaves a software engineer a lot of space for structuring the complex system with a more comprehensive abstraction.
This means that typical paradigms like classification and inheritance are used to reduce redundancy and duplication of data and attributes, but also for re-usability and extensibility.
In modeling technology it is common to use design patterns. IFC has utilized multiple design patterns in its specification, some of them producing sub-optimal artefacts. These were analyzed and alternative implementations were designed. One of them is the Type-Object Pattern. This pattern allows an object to be associated with a dynamic object type and, consequently, an object instance to be linked with a particular object type instance. This approach leads to lack of static type safety.
For this reason the pattern was redesigned using classification. This results in the following structure: The common properties associated with the type IfcWall (residing in the domain type layer) can be made binding by the fact that it is an instance of IfcWallType in the domain meta-type layer. IfcWallType can be seen in the following figure. As the type of both IfcWallStandardCase and IfcWallCollapsibleCase it can enforce the presence of any desired attributes.
 |
| Figure 1. on the right: the type-object pattern, on the left: its redesign |
-
Development of the meta-model
Through the process of analysis and simplification five main concepts were selected as basis for the meta-model of type IfcWall:
– Geometry
– Material Layer
– Path Connectivity
– Local Placement
– Properties and Quantities
The next figure shows the root diagram of the meta-model, where the IfcWallType has references to all maintained concepts described above. IfcWallType is the type of IfcWall. Consequently it enforces the references to all types that describe the concepts defining a IfcWall.
 |
| Figure 2. The class diagram of the domain meta-types relevant for IfcWall. |
- Testing
The domain classes such as IfcWall from the Shared Layer of IFC can now simply be instantiated from the newly developed domain meta-classes. As proof of the semantic equivalence of the generated model and the IFC model of IfcWall serves the comparison between the instances they produce. Those are based on an example contained in the IFC documentation on the buildingSmart website. Both semantic and quantitative metrics were used (e.g. number of objects and links).
Results
The comparison between the instances of the new model instantiated from our meta-model and the IFC standard model in the Testing section shows that instances of IfcWall differ in number of objects and links. However, semantically both instances are effectively the same.The meta-model has the following advantages and improvements over the IFC standard:
- Readability and Comprehensibility
The replacement of complex design patterns with classification resulted in fewer associations and reduction of attributes in the instantiated model. This makes it easier to read and comprehend than the standard IFC model. The reduction in complexity is also facilitated by the redesign of the objectified relationships typical of the standard. - Extensibility
The redesign of the type-object pattern allows the definition of type properties in the domain meta-type layer. An immediate consequence of that is that the number of available wall types can be extended. As demonstrated in the Figure 1, a new type of wall (not present in the current IFC standard) can be created in the domain type layer: The IfcCollapsableWall type represents a wall that can be collapsed. The definition of properties which describe the collapsing behavior is enforced by the type-instance relationship. - Type-Safety
The IFC standard is not type-safe because of type-to-object linking at instance level, as shown on the right side of Figure 1. The multi-level modeling paradigm removes this weakness by using the instantiating capabilities of the object-oriented development approach.